
Anthropic's Capacity Crisis: Rate Limits, the Inference Tax, and Who Wins the Compute Race
Users are hitting walls, big models are being throttled, and $65B in pledged capital won't translate into live capacity for 18–24 months — here's where Anthropic actually stands against OpenAI, Gemini


Executive Summary
In late March 2026, Anthropic quietly tightened Claude’s usage limits during weekday peak hours — 8 a.m. to 2 p.m. Eastern — as demand began exceeding available GPU capacity. Claude Pro users found themselves hitting daily message walls faster than they had a year prior. GitHub paused new Copilot signups in April 2026 citing unsustainable compute demand. And Claude Opus models were being stripped from lower subscription tiers. The proximate cause was Anthropic’s own success: Claude adoption had outrun the physical infrastructure to serve it.
This is not a new story in AI. In November 2022, OpenAI launched ChatGPT and the site promptly crashed. “At capacity” error messages became memes. The company launched a $20/month ChatGPT Plus waitlist in February 2023 specifically to manage demand while Microsoft’s Azure infrastructure was scaled in parallel. The question in 2026 is whether Anthropic is at the same inflection point — demand proved, infrastructure catching up — or whether its structural position in the compute race is fundamentally different from OpenAI’s. With $65B in pledged capital from Google and Amazon but an 18–24 month lag before that capital becomes live inference capacity, the answer is complicated.
01
The Parallel That Actually Matters: November 2022 to Today
On November 30, 2022, Sam Altman tweeted that OpenAI had launched “ChatGPT” as a research preview. It was meant to be a quiet experiment. Within five days, it had one million users. Within two months, it had 100 million — the fastest consumer application to that scale in history, beating TikTok’s previous record of nine months. The OpenAI servers, built for a few thousand researchers, began returning “ChatGPT is at capacity right now” error pages around the clock. Azure’s compute engineers were essentially rebuilding the plane while flying it.
The experience was genuinely disruptive for users, but in retrospect it validated something more important: product-market fit so strong that it overran the physical ability to serve it. Microsoft’s $10 billion investment announcement in January 2023 — revealed just weeks after the ChatGPT launch — was partly a product partnership and partly an emergency infrastructure backstop. The deal gave OpenAI access to Azure’s GPU clusters on terms that would have taken years to negotiate in a less urgent environment. Demand created negotiating leverage. Leverage became infrastructure. Infrastructure became the moat.
The 2026 Anthropic situation rhymes with 2022–2023 OpenAI more closely than most commentary acknowledges. Claude’s rate limit tightening, the GitHub Copilot pause, the tiered access changes — these are the signals of a model whose demand curve has bent sharply upward while its supply curve (new GPU capacity) takes 18–24 months to respond. The difference is that Anthropic has learned from the OpenAI playbook and has signed its infrastructure deals in advance: $40 billion from Google and $25 billion from Amazon, both structured to deliver compute in tranches as it comes online. The capital is committed. The capacity is not yet live. And users are feeling that gap in real time.
The ChatGPT Parallel, Side by Side: November 2022 — ChatGPT launches, site crashes within days. February 2023 — ChatGPT Plus ($20/month) launches as demand management. January 2023 — Microsoft announces $10B Azure backstop deal. Mid-2023 — Azure GPU capacity stabilizes serving experience. 2024 — OpenAI launches o1, GPT-4o; capacity sufficient for scale. Compare: Late 2025 / Early 2026 — Claude Opus demand outpaces serving capacity. March 2026 — Rate limits tightened during peak hours. 2024–2026 — Google ($40B) and Amazon ($25B) commit infrastructure. Late 2026 / 2027 — Trainium2, Trainium3, and expanded Google TPU clusters come online. The lag between “demand proved” and “capacity sufficient” was approximately 12–18 months for OpenAI. For Anthropic, the clock started ticking in late 2025.
02
Training vs. Inference: The Distinction Most Coverage Misses
When Anthropic announces a $40 billion Google deal or a $25 billion Amazon commitment, most coverage frames it as “Anthropic has the compute to train the next generation of Claude.” That framing misses the more immediately relevant bottleneck: inference. Training a frontier model is a one-time event that consumes enormous compute for weeks or months. Inference — serving that model to millions of users simultaneously, 24 hours a day — is a continuous, perpetual compute drain that scales with every new user and every new query.
The distinction matters because training and inference have different hardware requirements, different economics, and different bottlenecks. Training demands the highest-end accelerators (Nvidia H100/H200/B200, Google TPU v5) in tightly interconnected clusters because gradient computation requires fast chip-to-chip communication. Inference is more parallelizable — you can distribute queries across many chips — but the sheer volume of requests from millions of users requires an enormous number of chips running continuously. A model that takes $100 million to train might require $500 million or more per year in inference compute just to serve a mid-scale user base.
⚠ The Context Window Tax — Why Claude Opus Limits Hurt More Than They Look
1 Million Token Context Windows Are Extraordinarily Expensive to Serve
Claude Opus 4.6 supports a 1 million token context window — one of the largest in any deployed frontier model. That capability is genuinely impressive and enables use cases (analyzing entire codebases, processing book-length documents, multi-session agent workflows) that shorter-context models cannot perform. But serving a 1 million token context window query consumes roughly 4–8 times the inference compute of a standard 128K-context query on equivalent models. At a time when Anthropic’s inference capacity is already strained, every long-context query effectively “uses” the capacity of 4–8 standard queries.
This is not a hardware problem that money immediately solves. It is an inference cost structure problem: Anthropic’s flagship capability (the largest context window commercially deployed) is also its most expensive-to-serve capability, and it is being used increasingly by enterprise customers who are the primary market for those long-context features. The rate limit tightening in March 2026 was partly driven by a surge in enterprise long-context usage that consumed capacity at a rate Anthropic’s infrastructure team had not fully modeled at the volume seen.
The deliberate throttling documented by users — adaptive thinking defaulting to “medium” effort rather than “high,” reasoning steps being redacted from the UI — are inference cost management decisions, not capability limitations. Anthropic is effectively load-balancing by reducing compute per query during peak periods. It is the AI equivalent of a restaurant stopping the extended tasting menu during a Saturday night rush and serving the standard menu instead.
03
The Compute Race: Who Has What, Right Now and in 2027
Measuring AI compute capacity across companies is not a precise science. Companies don’t publish GPU counts or power consumption for competitive and security reasons. What we can measure are announced investments, data center power commitments (in gigawatts), and inferred GPU counts from construction permits, utility filings, and earnings disclosures. The chart below uses these publicly available signals to estimate current operational AI compute capacity and projected 2027 capacity for the five primary frontier AI actors.
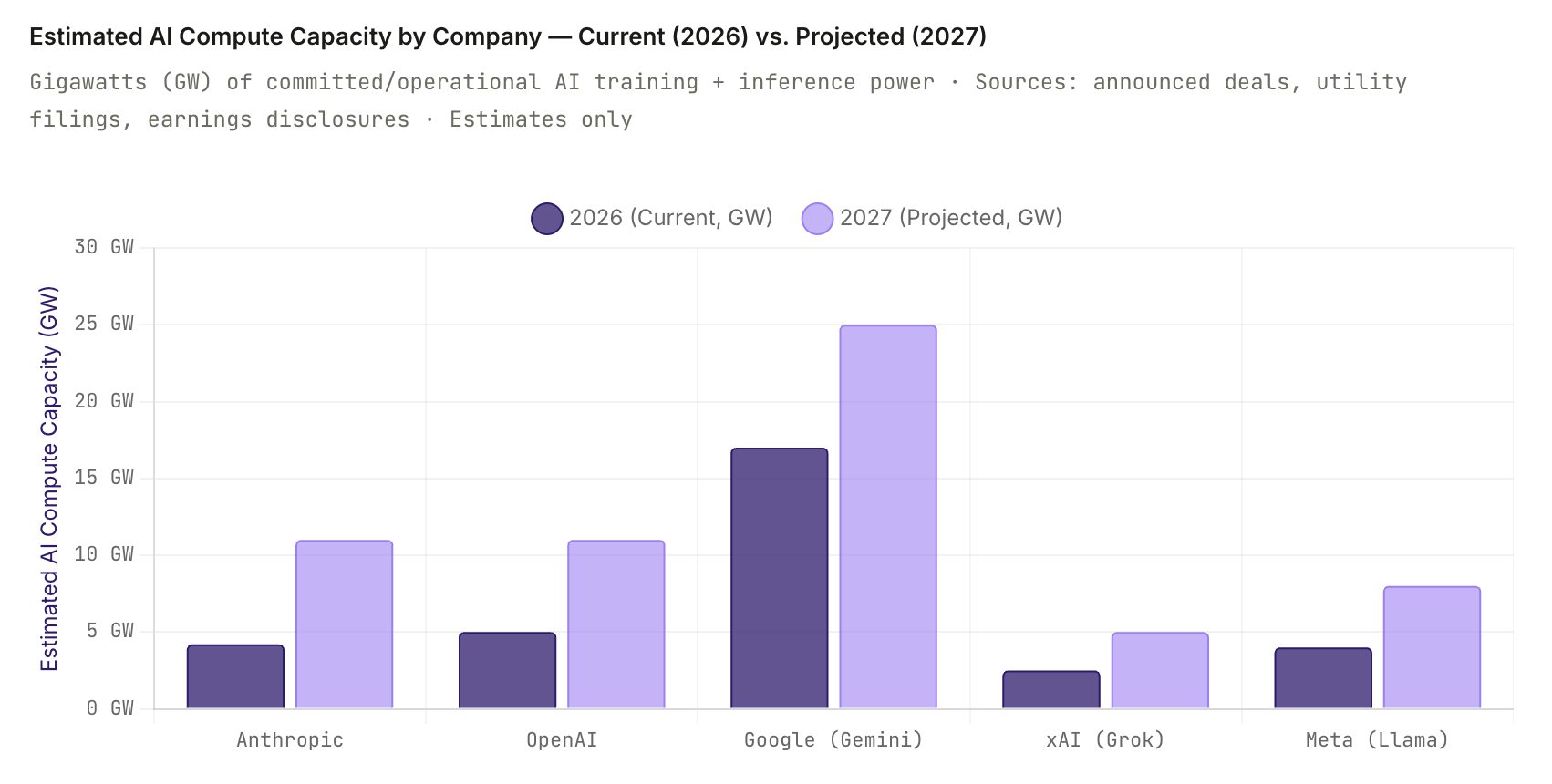
Google's apparent dominance in the chart reflects its unusual position: it is both a compute supplier (to Anthropic and others) and a consumer of that same compute for Gemini. The TPU infrastructure Google is deploying for Anthropic is additive to Google's own AI capacity, not a transfer of existing resources. Microsoft's position is similarly inflated by its role as a general-purpose cloud provider — not all of that AI compute is dedicated to OpenAI's models. The more relevant competitive metric for frontier model companies is dedicated inference capacity for their flagship models, which narrows the field considerably.
04
The Five-Company Compute Scorecard
The Constrained Challenger — Now Better-Capitalized
Anthropic / Claude
The most powerful models per benchmark, the least owned infrastructure — but that picture shifted significantly on May 6, 2026. Anthropic now has agreements spanning Google ($40B), Amazon (up to 5 GW by end of 2026+), SpaceX (220,000+ NVIDIA GPUs, 300 MW, live within weeks), Microsoft + NVIDIA ($30B Azure), and Fluidstack ($50B U.S. infrastructure). The SpaceX deal is the most immediately impactful: unlike the long-horizon Google and Amazon tranches, the Colossus 1 capacity arrives within one month and directly addresses the peak-hour rate limit problem. Future plans include working with SpaceX on orbital AI compute — potentially gigawatts of space-based inference, a timeline and ambition that goes well beyond any current competitor.
Note: SpaceX and xAI are separate Musk entities. Colossus 1 is SpaceX’s supercomputer, distinct from xAI’s Memphis facility. Anthropic sourcing capacity from a Musk company while xAI/Grok competes in the model market is a notable structural dynamic.
Current: ~3.8–4.5GW (updated with SpaceX) · 2027E: ~10–12GW (revised up) · Ownership: 0% (cloud-dependent) · Rate limits: Easing — SpaceX capacity arriving June 2026
The Stargate Builder
OpenAI / GPT
OpenAI’s compute position has transformed since the 2022–2023 crash era. The Stargate project — a joint venture with SoftBank, Oracle, and Microsoft — is building a $500B AI infrastructure network across the U.S. The first Stargate facility in Abilene, Texas is slated for mid-2026 with 1.2 gigawatts of capacity and approximately 400,000 Nvidia B200 GPUs. OpenAI also has preferential access to Azure compute through its Microsoft partnership, which provides serving capacity for ChatGPT and the API. The structural advantage: OpenAI is moving toward infrastructure ownership rather than cloud dependency, which reduces its exposure to the compute pricing dynamics that make Anthropic’s situation so difficult to model.
Current: ~4–6GW (Azure + early Stargate) · 2027E: ~10–12GW · Ownership: Partial (Stargate JV) · Rate limits: Managed via tiered pricing
The Vertically Integrated Giant
Google / Gemini
Google’s position is categorically different from every other player in this analysis. Google designs its own accelerators (TPU v5, Trillium), builds its own data centers, owns its own power infrastructure (including solar and wind assets), and operates a hyperscale cloud business (GCP) that generates the revenue to fund unlimited compute investment. Gemini runs on infrastructure Google controls end-to-end — no third-party dependency, no cloud contract risk, no capacity queue behind other customers. The flip side: Google’s organizational complexity (multiple competing AI teams — DeepMind, Google Brain, Google Research — now nominally unified under DeepMind) has historically slowed its model iteration speed relative to OpenAI and Anthropic.
Current: ~15–20GW (Google total AI) · 2027E: ~25GW+ · Ownership: 100% · Rate limits: Minimal for Gemini Advanced
The Fastest Scaler
xAI / Grok
Elon Musk’s xAI has executed the fastest datacenter build in modern history. Colossus 1 in Memphis went from concept to 100,000 Nvidia H100 GPUs in approximately 122 days — a construction speed that required creative procurement (renting neighboring Tesla Megapack power units, using industrial-scale generators as temporary power) that would have been impossible without Musk’s personal relationships with power utilities and GPU suppliers. Colossus 2 targets 1 million GPUs and 1 gigawatt of power, with Musk projecting 3 gigawatts of total xAI capacity by mid-to-late 2026. These are aggressive targets and the history of ambitious datacenter timelines suggests meaningful slippage. But even at 50% of the projected build, xAI would emerge as a genuine compute heavyweight by 2027.
Current: ~2–3GW (Colossus 1 + early C2) · 2027E: ~4–6GW (50–60% of Musk’s target) · Ownership: 100% (owned) · Rate limits: Grok X.com limits on free tier
The Consumer Giant
Meta / Llama
Meta’s AI compute story is fundamentally different because its primary output — Llama — is open-source. Meta builds compute not to generate inference revenue but to power its own advertising systems and to advance foundational AI research that it gives away. The Prometheus supercluster in New Albany, Ohio is targeting 1 gigawatt and approximately 500,000 GPUs when complete in 2026. Meta’s total 2026 AI capital expenditure is projected at $65–72 billion. The open-source positioning means Meta is not competing directly for inference market share with Anthropic or OpenAI, but its massive compute investments set a capability benchmark that raises the bar for all frontier model developers.
Current: ~3–5GW · 2027E: ~7–9GW · Ownership: 100% · Model access: Open-source (Llama 4)
05
Anthropic’s Capacity Timeline: 6, 12, 18, and 24 Months
The honest answer to “when will Claude’s rate limits improve?” is driven almost entirely by the physical timeline of hardware deployment. Signing a billion-dollar compute deal does not produce a single additional GPU-hour of serving capacity until the chips are manufactured, shipped, installed, networked, powered, and integrated into Anthropic’s serving stack. That process, even for a company with Google’s and Amazon’s logistics capabilities, takes time that cannot be shortened by capital.
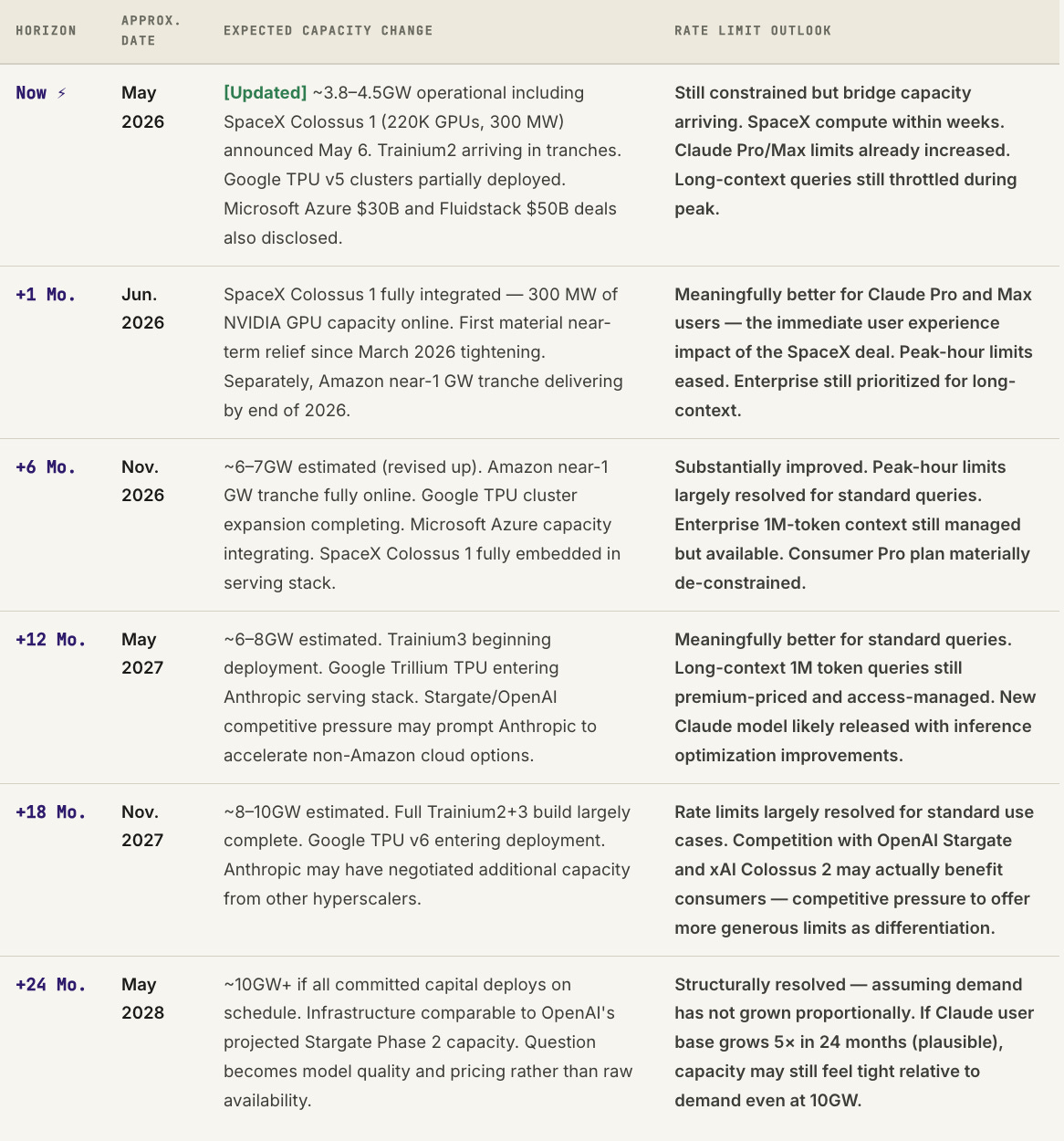
The key caveat in every row of that table: these projections assume Anthropic’s user base and query volume grow at roughly current rates. The history of AI adoption suggests this is a conservative assumption. If Claude’s agentic capabilities (the focus of Opus 4.7 and likely Claude 5) drive a step-change in average session length and compute-per-user, the demand curve could easily outrun the supply expansion on a 2-year horizon even with full capital deployment.
06
