
Broadcom: The Hidden AI Winner
Part 2 of The Hidden AI Winners Series — Why Networking and Custom Silicon May Capture More Durable AI Profits Than GPUs


Disclaimer: This report is for informational purposes only and does not constitute investment advice, a recommendation, or a solicitation to buy or sell any security. All data is sourced from public filings, earnings releases, and third-party research as of February 28, 2026. Past performance is not indicative of future results. Investing in early-stage companies carries substantial risk of loss.
Executive Summary
Broadcom Inc. (NASDAQ: AVGO) has quietly assembled the most diversified structural position in the AI infrastructure economy. While NVIDIA dominates the GPU narrative and commands the market’s attention, Broadcom controls two equally critical chokepoints: the networking fabric that connects AI accelerators and the custom silicon that hyperscalers increasingly prefer over general-purpose GPUs.
In fiscal year 2025 (ended November 2025), Broadcom delivered record consolidated revenue of $64 billion, up 24% year-over-year. AI semiconductor revenue reached $20 billion, growing 65% annually, while infrastructure software (predominantly VMware) contributed $27 billion at a 93% gross margin. Free cash flow surged 39% to $26.9 billion. The company exited the year with an AI backlog exceeding $73 billion.
Management expects AI semiconductor revenue to double year-over-year in Q1 FY2026 to $8.2 billion, driven by custom accelerator ramps for Google, Meta, and OpenAI. By fiscal 2027, Broadcom projects $60–$90 billion in annual AI semiconductor revenue from its three largest hyperscaler customers alone — before accounting for recently disclosed partnerships with Anthropic and a fifth unnamed hyperscaler.
In Part 1 of this series, we analyzed Vertiv as the solution to the AI economy’s power bottleneck. In Part 2, we turn to the data bottleneck — and to the company that has positioned itself as both the wiring and the brain of hyperscale AI infrastructure.
Coming Next in The Hidden AI Winners Series
This series systematically maps every critical layer of the AI infrastructure economy. Each article answers the same question: Is this business structurally positioned to capture durable profits from the AI buildout between 2025 and 2030?

Key Takeaways for Broadcom
Investment Highlights
AI semiconductor revenue grew 65% to $20B in FY2025, with Q4 accelerating to 74% YoY growth. Management guides for AI revenue to double YoY in Q1 FY2026, reaching $8.2B in a single quarter.
Broadcom has secured custom silicon relationships with at least five hyperscalers — Google, Meta, OpenAI, Anthropic, and one undisclosed — creating a design-in moat with 3–5 year switching costs per engagement.
Ethernet is overtaking InfiniBand in new AI cluster deployments, and Broadcom holds over 80% of the high-end Ethernet switching silicon market.
Infrastructure software (VMware) delivers $27B in revenue at 93% gross margin and 78% operating margin, providing a recurring cash flow foundation that de-risks the cyclical semiconductor business.
Free cash flow of $26.9B (42% FCF margin) supports $17.5B in annual shareholder returns while funding R&D investment in next-generation 3nm and 2nm custom silicon.
At $1.5T market cap and ~36x forward earnings, AVGO trades at a premium to semiconductor peers — but the AI backlog, VMware margin expansion, and custom silicon pipeline provide structural growth visibility through 2028.
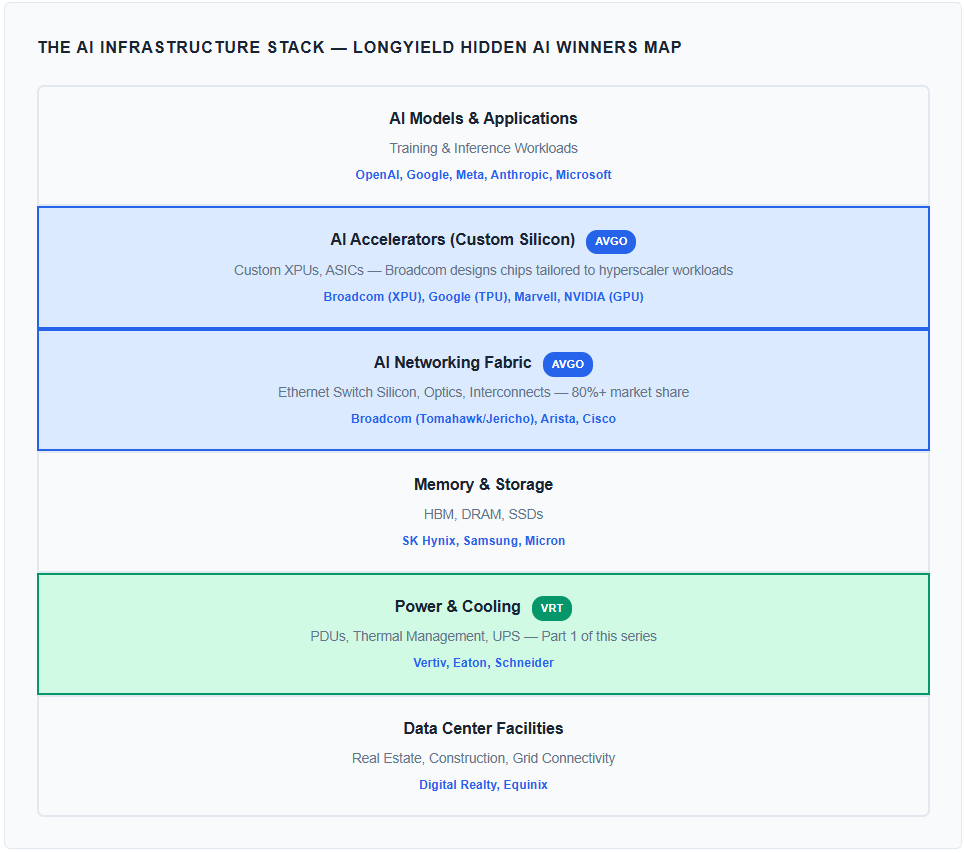
Where Broadcom Fits in the AI Infrastructure Stack
In Part 1, we introduced a framework for analyzing the AI infrastructure economy beyond GPUs. Vertiv represented the physical layer: the power distribution and thermal management systems without which no AI cluster can operate. Vertiv solves the power bottleneck.
Broadcom solves the data bottleneck. No matter how many accelerators a hyperscaler deploys, those chips are useless in isolation. Training a frontier model requires thousands of accelerators communicating simultaneously — exchanging gradients, synchronizing parameters, and moving terabytes of data per second across a fabric of switches and interconnects. Broadcom builds the silicon that powers that fabric.
And increasingly, Broadcom is building the accelerators themselves. Through its custom silicon (XPU) platform, Broadcom co-designs bespoke AI chips with hyperscalers who want performance optimized for their specific workloads — at lower cost and higher efficiency than general-purpose GPUs. This positions Broadcom on both sides of the data bottleneck: moving the data and processing it.
Both Vertiv and Broadcom are structural enablers — companies whose products are embedded deep in the infrastructure stack, where switching costs are high and demand scales in lockstep with AI compute expansion. The difference is the layer: Vertiv captures value from physical infrastructure; Broadcom captures value from data infrastructure.
I. The AI Networking Bottleneck
The fundamental architectural challenge of AI training is parallelism. A frontier large language model requires distributed training across thousands — soon tens of thousands — of accelerators working in concert. Every training step requires all-reduce operations where gradients computed on each accelerator must be aggregated, averaged, and redistributed across the entire cluster. The bandwidth and latency of the network fabric directly determines how efficiently those accelerators are utilized.
Put simply: a cluster of 10,000 GPUs connected by a slow network behaves like 2,000 GPUs. The networking fabric is the multiplier that converts raw silicon into useful compute.
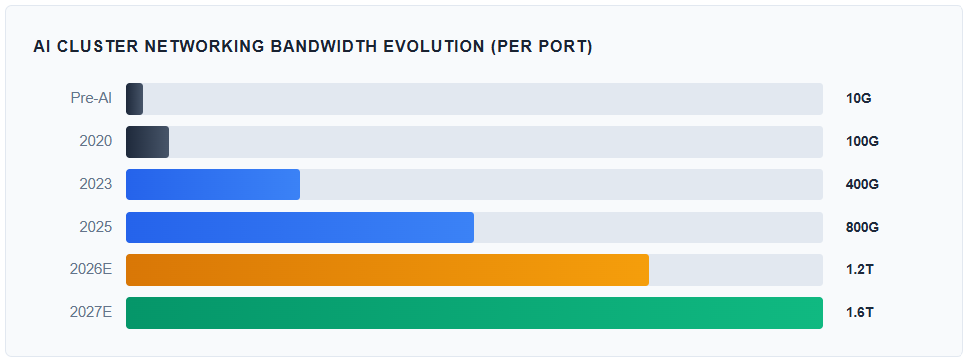
Bandwidth Evolution
AI cluster networking speeds have evolved dramatically to keep pace with accelerator performance. Each new generation of GPU or custom silicon demands proportionally faster interconnects. The industry has moved from 10 Gbps Ethernet in pre-AI data centers to 400G and 800G in current deployments, with 1.6 Tbps switches now entering production.
Every GPU dollar spent creates proportional networking demand. As hyperscalers scale clusters from 10,000 to 100,000+ accelerators, the networking bill scales super-linearly — because larger clusters require more switching layers (spine-leaf architectures) and higher aggregate bandwidth. Dell’Oro Group estimates the AI networking market will grow from approximately $15 billion in 2024 to over $80 billion by 2028.
II. Broadcom’s Business Model
Broadcom operates through two primary segments that combine to create a business model unlike any other in the semiconductor industry: a high-growth semiconductor division riding the AI wave, and a high-margin recurring software franchise anchored by VMware.
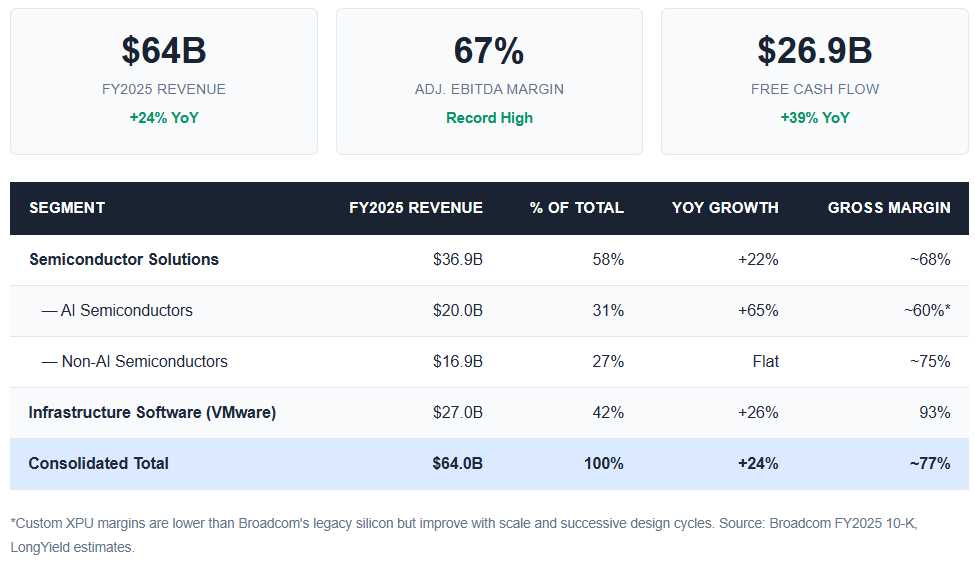
The VMware franchise is strategically essential. After the $69 billion acquisition closed in late 2023, Broadcom aggressively transitioned VMware’s 10,000 largest customers from perpetual licenses to subscription-based VMware Cloud Foundation (VCF) bundles. Software operating margins expanded from 72% to 78% within a year. This creates a $27 billion recurring revenue base with exceptional cash generation — effectively funding Broadcom’s R&D investment in AI silicon without diluting shareholders or assuming additional debt.
III. Custom AI Accelerators — Broadcom’s Most Important Opportunity
The GPU has been the default AI accelerator for the past decade, and NVIDIA has built a $200+ billion annual business on that dominance. But the hyperscalers — the largest buyers of AI compute — are increasingly pursuing an alternative: custom-designed application-specific integrated circuits (ASICs) optimized for their proprietary workloads.
Google was first, developing its Tensor Processing Unit (TPU) with Broadcom’s silicon design expertise. Google’s latest TPU v7 (Ironwood), fabricated on TSMC’s 3nm process, is designed specifically for inference and reasoning workloads — delivering higher throughput per watt than general-purpose GPUs for Google’s specific model architectures. Meta followed with its MTIA v2 accelerator, also built in partnership with Broadcom. And in 2025, OpenAI and Anthropic both disclosed multibillion-dollar custom silicon programs with Broadcom, with mass production targeted for 2026.
Why Hyperscalers Want Custom Silicon
The economics are compelling. General-purpose GPUs include transistors and capabilities that any given hyperscaler may not need. Custom chips strip away the unnecessary circuitry and optimize die area for the specific operations — matrix multiplications, attention mechanisms, memory bandwidth patterns — that each hyperscaler’s models actually use. The result is a chip that delivers 30–50% better performance per watt for that specific workload, at a lower per-unit cost at scale.
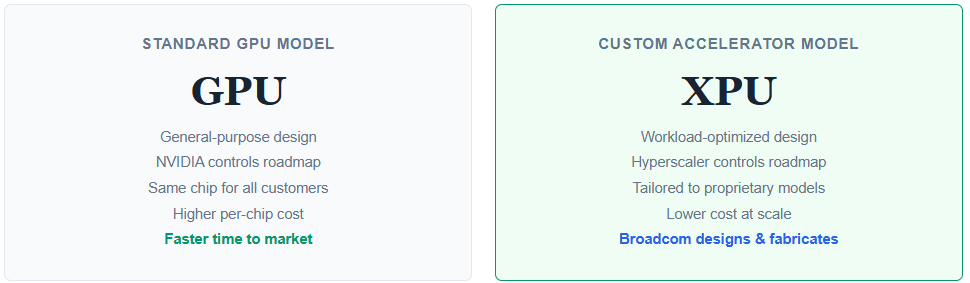
Broadcom’s role in this model is analogous to an architecture firm: the hyperscaler provides the specifications and requirements, and Broadcom’s engineering team designs the chip, manages the TSMC fabrication relationship, and delivers the finished silicon. Broadcom’s 3.5D XPU platform — integrating compute dies, I/O tiles, and HBM memory in a single package — has become the industry standard for custom AI accelerators.
The Scale of the Opportunity
Broadcom management projects $60–$90 billion in annual AI semiconductor revenue by FY2027 from just three hyperscaler customers. The AI backlog now exceeds $73 billion. With Anthropic’s $11B order and a fifth undisclosed hyperscaler, the total addressable pipeline is significantly larger than these figures suggest.
The moat here is design-in stickiness. Each custom silicon engagement takes 2–3 years from initial architecture to volume production. Once a hyperscaler commits to Broadcom’s XPU platform, switching to a competitor (Marvell, for example) requires redesigning the chip, requalifying the manufacturing process, and rewriting the software stack — a process that takes years and costs billions. These are not transactional relationships; they are partnerships measured in decades.
IV. Broadcom’s AI Networking Dominance
Beyond custom silicon, Broadcom controls the other critical layer of the AI data infrastructure: Ethernet switching. Broadcom’s Tomahawk and Jericho switch silicon families power the vast majority of high-performance Ethernet switches deployed in hyperscale data centers. The company holds an estimated 80%+ share of the high-end Ethernet switching silicon market.
The Ethernet vs. InfiniBand Shift
In 2023, NVIDIA’s InfiniBand technology held over 80% of AI back-end networking deployments. InfiniBand offered lower latency and was tightly integrated with NVIDIA’s GPU ecosystem. But the industry has undergone a dramatic shift. By 2025, Ethernet surpassed InfiniBand in new AI cluster deployments — a reversal driven by three factors:
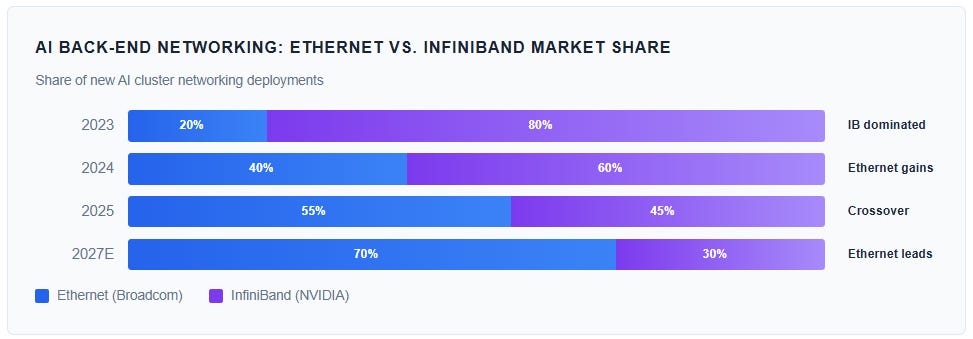
First, Ethernet is an open standard that avoids vendor lock-in — a critical consideration for hyperscalers spending tens of billions annually on infrastructure. Second, the Ultra Ethernet Consortium (UEC) released UEC 1.0 in June 2025, a specification that reconstructs the Ethernet network stack to achieve InfiniBand-like latency performance. Third, Ethernet scales more cost-effectively in extremely large clusters (100,000+ accelerators), where InfiniBand’s centralized subnet management becomes a bottleneck.
This secular shift from InfiniBand to Ethernet is a structural tailwind for Broadcom. NVIDIA owns InfiniBand. Broadcom owns Ethernet switching silicon. As the market shifts, Broadcom’s addressable market expands dramatically.
