
Cerebras Systems: The Memory Wall
Cerebras built a chip the size of a dinner plate to solve a bottleneck most people don't know exists. Here's what that means, what they've signed, and what could go wrong.


In the summer of 2024, Cerebras uploaded a benchmark to its website showing its inference system answering questions at 1,800 words per second — roughly the pace of an auctioneer reading a novel aloud. The comparison being made was to NVIDIA GPU clusters from hyperscale clouds, which answer at closer to 80–90 words per second on the same model. The gap was so large that the AI community’s initial response was skepticism. The gap is real, and it is structural — not a software trick, not cherry-picked workloads, but a consequence of a hardware architecture that solves a problem that NVIDIA’s architecture was not designed to solve. Understanding why is the whole story. Everything else — the $24.6 billion backlog, the OpenAI contract, the May 2026 IPO, the valuation debate — follows from it.
§ 01 — The Physics
Why your GPU is slow at talking — and what Cerebras did about it
Start with the problem, because it is genuinely counterintuitive. You might expect AI inference to be a compute-limited problem: generating text sounds like a lot of math. In fact, for the kind of autoregressive generation modern LLMs perform — generating one token at a time, with each token dependent on everything that came before — the binding constraint is almost entirely memory bandwidth. Not raw math. Memory speed.
Here is why. Every time an LLM generates a word, it must load the entire model’s weights from memory into the processor. For a 70-billion parameter model like Llama 3.1 70B, that means moving roughly 140 gigabytes of data (at 2 bytes per parameter) through the memory system — for every single token. At 100 tokens per second, that is 14 terabytes per second of memory reads. The arithmetic doesn’t change whether the model is doing something “hard” like complex reasoning or “easy” like completing a sentence. Every word requires the same full sweep through memory. The processor is mostly waiting for the data to arrive.
The filing cabinet analogy — for finance readers
Imagine you’re a trader who needs to reference every page of a 10,000-page prospectus before making each trade decision. With a standard GPU cluster, the prospectus is stored in a warehouse across town. You have a fast truck, but the warehouse is far, and the truck makes the same round trip for every single decision. The math you do once the pages arrive takes microseconds. The trip takes seconds.
Cerebras moved the warehouse into the trading desk. Their chip stores the equivalent of that prospectus in on-chip memory with a direct connection to every processor simultaneously. No truck. No trip. The data is already there.
The technical term is memory bandwidth. Cerebras’s WSE-3 delivers 21 petabytes per second of on-chip bandwidth — 7,000 times more than NVIDIA’s H100. That is not a rounding-error advantage. It is a structural architectural difference that produces 20–75× faster token generation on the same models.
The reason NVIDIA’s architecture has this constraint is not incompetence. GPUs were designed for a different world — rendering 3D graphics, then training neural networks in large parallel batches. Training is compute-bound: you process thousands of examples simultaneously, and raw FLOPS matter most. For this task, packing lots of fast processors onto a chip and connecting them via high-speed interconnects to external HBM memory is the right design. NVIDIA has iterated on this architecture across more than a decade of AI work, and it remains excellent for training.
Inference is different. Inference means generating tokens one at a time, in sequence, in response to a user’s specific prompt. You cannot parallelize across thousands of simultaneous training examples; you are answering one question. The workload is fundamentally memory-bandwidth-limited, not compute-limited. And NVIDIA’s architecture, which puts the bulk of memory outside the chip connected via high-bandwidth but still-external buses, runs into physics: the data has to travel, and travel takes time.
What Cerebras actually built
Cerebras’s answer was radical enough that most semiconductor engineers, when it was first proposed in 2016, said it was impossible. Rather than cutting a silicon wafer into hundreds of individual chips and connecting them via packaging, they kept the entire wafer intact as a single chip. The Wafer Scale Engine 3 (WSE-3) is a square of silicon 21.5 centimeters to a side — the surface area of a large dinner plate — fabricated on TSMC’s 5-nanometer process. The result:

The engineering trick that makes this possible is a fail-in-place architecture. A standard GPU chip is cut to specification after the wafer is inspected; any defective chip is discarded. At wafer scale, you cannot cut around defects — you accept them. The WSE-3 ships with approximately 70,000 dead cores by design, the interconnect fabric routing permanently around them. The chip works through redundancy, not perfection. It was a counterintuitive but ultimately necessary solution: you cannot manufacture a chip the size of a plate and expect every transistor to be perfect.
The practical implications of on-chip co-location go beyond speed. Data that never leaves the chip cannot be intercepted or leaked. For sensitive enterprise workloads — financial modeling, legal discovery, clinical research — that privacy guarantee has independent commercial value beyond raw throughput. It is a secondary selling point that shows up in Cerebras’s enterprise deals without getting mentioned in the benchmark press releases.
§ 02 — The Performance Gap
What the benchmark numbers say — and what they don’t
The performance comparisons published by Cerebras and independently corroborated are striking enough that they bear quoting precisely, because the magnitudes matter for the business case. These are not marginal improvements; they are order-of-magnitude gaps.
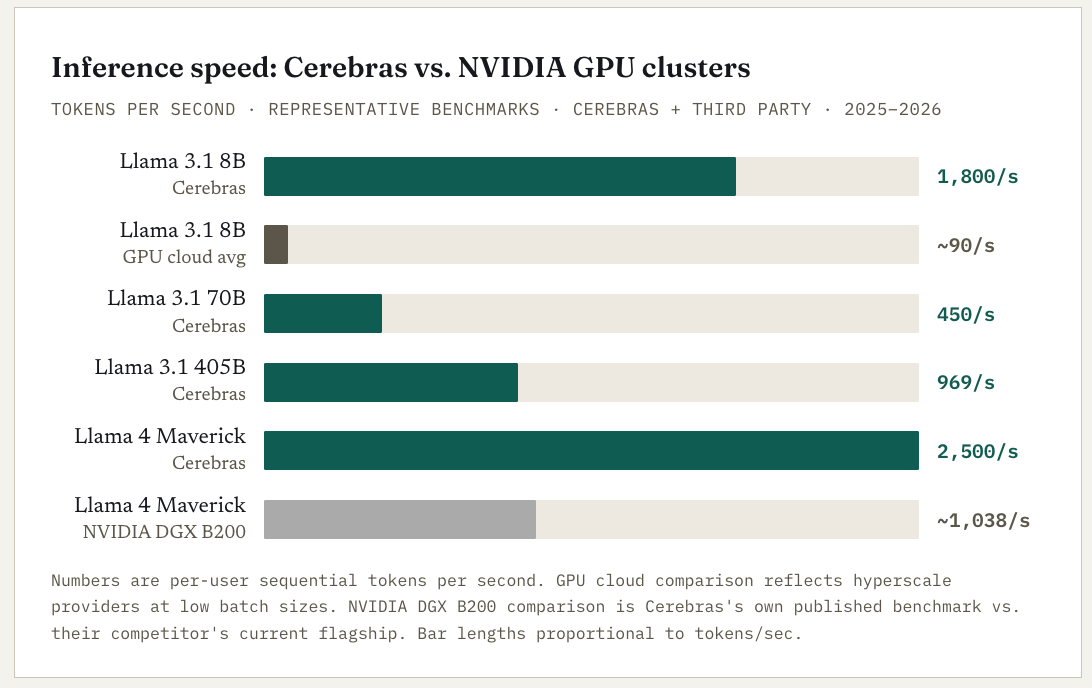
Three caveats that any serious reader should carry into these numbers. First, Cerebras publishes some of these benchmarks themselves — they are subject to cherry-picking on favorable workloads. Independent third-party results broadly corroborate the direction and rough magnitude of the advantage, but the precise multiples should be treated as indicative rather than gospel. Second, the advantage is largest for sequential inference — single-user, single-stream token generation. For highly batched workloads (many simultaneous users processed together), NVIDIA’s architecture can spread the memory load across requests more efficiently and the gap narrows, though Cerebras remains faster. Third, raw speed is not always the value-added feature that customers are buying.
Latency matters most for real-time, interactive, agentic use cases — AI that responds at human conversational speed or faster, AI that executes multi-step tasks where each step waits for the previous result. It matters less for background batch processing where speed translates primarily to cost savings rather than user experience. That distinction between latency-critical and cost-critical use cases is important for understanding where Cerebras wins and where NVIDIA holds its ground.
For AI agents executing multi-step reasoning chains — where the next step cannot begin until the previous step completes — faster inference means faster task completion, which means more tasks per unit of time. OpenAI’s head of infrastructure described it as enabling “faster responses, more natural interactions, and a stronger foundation to scale real-time AI to many more people.” That language points at a specific use case: the interactive, always-on AI assistant that users expect to respond like a fast human, not a slow server. An AI agent running at 1,800 tokens per second instead of 90 is not just 20× faster — it is the difference between a system that users experience as instantaneous and one that feels like a loading bar. In agentic workflows where an AI executes 50-step task chains autonomously, that difference compounds into minutes versus hours.
§ 03 — The Business They Built
