
Inference Economics: The Hidden War Nobody Is Talking About


OpenAI will lose $14 billion this year on $25 billion in annualized revenue. The cost to serve a million tokens has fallen 25x in 18 months. NVIDIA just posted $81.6 billion in quarterly revenue. These three facts exist simultaneously — and together, they describe the most consequential infrastructure battle in technology's history. Here is every dimension of what is at stake.
01
01 · The Thesis — Two Numbers That Don’t Add Up
There are two numbers at the center of everything happening in artificial intelligence right now, and they do not belong in the same sentence. The first: OpenAI generated an annualized revenue run rate approaching $25 billion as of Q1 2026 — up from $20 billion at end-2025 — while sustaining a $14 billion operating loss — meaning the company spends $1.70 for every dollar it earns. The second: the cost to process one million tokens has fallen from roughly $2.50 in early 2025 to below $0.10 by mid-2026, a more than 25-fold decline in under eighteen months. Together, these two facts describe a company — and an industry — trapped in a cost structure that is simultaneously collapsing and not collapsing fast enough.
For institutional investors trying to make sense of the AI infrastructure buildout, this tension is the story. It is not a sidebar. It is not a transitional growing-pain that will resolve itself once models reach maturity. It is the fundamental economic question of the AI era: who controls the marginal cost of AI computation, how that cost will evolve, and which participants in the value chain will be left holding the bill when the accounting finally resolves. This article is a systematic attempt to answer that question across every relevant dimension — from silicon architecture to lab-level P&Ls to the paradoxical demand dynamics that may make cheaper AI more expensive in the aggregate.
The central argument of this analysis is that AI inference — the process of running a trained model to generate outputs — has become the critical battleground in the AI economy, displacing model training as the dominant cost and strategic concern. This shift was predictable and is now undeniable. What was not fully anticipated is the emergence of a multi-layer competitive war across silicon design, software optimization, and vertically integrated cloud infrastructure that will restructure the economics of every participant in the AI supply chain over the next three to five years.
Investors who treat this as merely a semiconductor story are missing half of it. Those who treat it as purely a cloud computing story are missing the other half. The real story is a simultaneous race to the bottom in token cost and a race to capture the demand explosion that cheaper inference will unlock — a classic Jevons dynamic playing out in real time across hundreds of billions of dollars of capital allocation.

The asymmetry between OpenAI’s cost structure and NVIDIA’s gross margins — 75% on $81.6 billion of quarterly revenue — is not a coincidence. It is the structural story of this moment. The companies building AI applications are bleeding cash to serve users, while the companies supplying the hardware those applications run on are operating at margins that most industries would consider fictional. That gap cannot persist indefinitely. Either inference hardware gets cheaper, or AI applications get more valuable, or both — and the timing and sequencing of those adjustments will determine who wins and who does not survive the transition.
Core Investment Thesis
The inference cost curve is not linear. It is being shaped by competing forces — hardware commoditization, reasoning model cost inflation, Jevons demand expansion, and vertically integrated silicon strategies — that create radically different outcomes for different participants. The companies that control inference economics will control the AI economy. Most of the most consequential action is happening outside public markets.
02
02 · What Is Inference? The Cost Side of AI No One Talks About
The AI industry has spent the past four years talking primarily about training — the process by which a language model learns its capabilities by processing enormous datasets across vast GPU clusters over weeks or months. Training runs at frontier scale cost hundreds of millions of dollars and require exquisite project management, dataset curation, and hardware reliability. They are dramatic. They make headlines. They generate the benchmark scores that analysts obsess over. And they are, increasingly, not the point.
Inference is what happens after training — the process of running a trained model to produce actual outputs. Every time you query ChatGPT, every API call an enterprise makes to generate a customer service response, every code completion suggested in an IDE, every contract summary generated from a legal document — these are all inference events. Unlike training, which happens once per model version on dedicated hardware, inference happens billions of times per day, continuously, at scale. The economics are entirely different.
Training Compute
One-time cost to build model capability. Dominated by GPU clusters running for weeks. Amortized over model lifetime. Declining as a share of total AI spend.
Inference Compute
Recurring cost to serve every user query. Scales directly with usage. Now represents the dominant ongoing cost for deployed AI systems. The focus of this analysis.
Token
The unit of inference economics. Roughly 0.75 words. Models consume input tokens and generate output tokens — pricing is per-million tokens. Output tokens cost more to generate than input tokens cost to process.
Latency vs. Throughput
Two competing optimization targets for inference hardware. Interactive applications demand low latency (fast first-token response). Batch processing applications prioritize throughput (maximum tokens per second per dollar).
KV Cache
Memory storing computation results during inference to avoid redundant work. Efficient KV cache management is critical for multi-turn conversations and long-context applications. A key differentiator for inference hardware.
FLOPS/token
The fundamental unit of inference efficiency. Determines hardware requirements per query. Reduced by quantization, sparsity, and architectural innovations like Mixture of Experts. The metric that determines cost per token.
The shift from training-dominated to inference-dominated AI economics is not subtle. Research from multiple sources suggests that by 2025, inference already accounted for more than 60% of total AI compute spend, and that share is rising rapidly as deployed models handle increasing query volumes. When OpenAI serves ChatGPT to 100 million daily active users, and when enterprise customers make billions of API calls monthly, the marginal cost of each output token accumulates into the largest single line item on the company’s P&L. The $14 billion loss projected for 2026 is, in very large part, an inference cost problem.
What makes inference so economically challenging is that it does not benefit from the learning curve effects that govern training. Training compute costs decline as researchers find more efficient training methods, as hardware improves, and as the same model can be reused for longer. Inference costs scale with deployment — more users, more cost, in a relationship that is uncomfortably close to linear for most current architectures. The only way to escape this linearity is through fundamental changes in how models are served: better hardware, more efficient software, architectural innovations that reduce the FLOP count per token, or delivery at the hardware level closest to the user.
Why This Matters Now
The inference problem was always latent in the AI business model. What has changed in 2025–2026 is threefold: the scale of deployment has made the cost visible and acute; the emergence of reasoning models has dramatically increased per-query compute requirements; and a serious competitive alternative to NVIDIA GPUs for inference workloads has finally arrived in volume. These three changes are happening simultaneously, which is what makes the current moment both chaotic and investable.
03
03 · The Token Price Collapse — 25x in 18 Months
To appreciate the velocity of what has happened to inference pricing, it helps to trace the curve from its starting point. In 2023, GPT-4 was priced at approximately $30 per million tokens — a figure that, in retrospect, reflected not just compute costs but the enormous scarcity premium commanded by the only frontier model available at commercial scale. Enterprise customers paid it because there was no alternative, and because the value proposition justified the cost when usage was limited. By early 2025, GPT-4o had repriced the market to approximately $2.50 per million tokens ($2.50 input / $10.00 output) — an 88% reduction in under two years, achieved through a combination of hardware improvements, software optimization, distillation techniques, and competitive pressure from open-source models. OpenAI subsequently launched GPT-5 in August 2025 and GPT-5.5 in April 2026 as the flagship frontier models, the latter priced at $5.00/$30.00 per million input/output tokens — a premium tier that coexists with, rather than replaces, the legacy GPT-4o endpoint which remains in production at its legacy price.
The pace of decline did not slow in 2025. It accelerated. From the $2.50 baseline of early 2025, token costs for commodity-grade models have collapsed to below $0.10 per million tokens by mid-2026 — with models like Gemini 2.5 Flash-Lite ($0.10/$0.40 per million tokens), Gemini 3.1 Flash-Lite ($0.25/$1.50 per million tokens), DeepSeek V3 ($0.14/$0.28 per million tokens), and ultra-budget options such as Mistral Nemo as low as $0.02 per million tokens for both input and output. (Google’s current frontier Flash-tier model, Gemini 3.5 Flash, launched in May 2026 at $1.50/$9.00 per million tokens — a premium over its predecessors that reflects its frontier-intelligence positioning; the workhorse mid-tier is Gemini 2.5 Flash at $0.30/$2.50 per million tokens.) The headline figure — from $2.50 per million tokens in early 2025 to below $0.10 per million tokens by mid-2026 — represents a more than 25-fold compression in under eighteen months. In annualized terms, this is a cost deflation rate that makes Moore’s Law look pedestrian. No other infrastructure cost in technology has declined this rapidly at this scale.
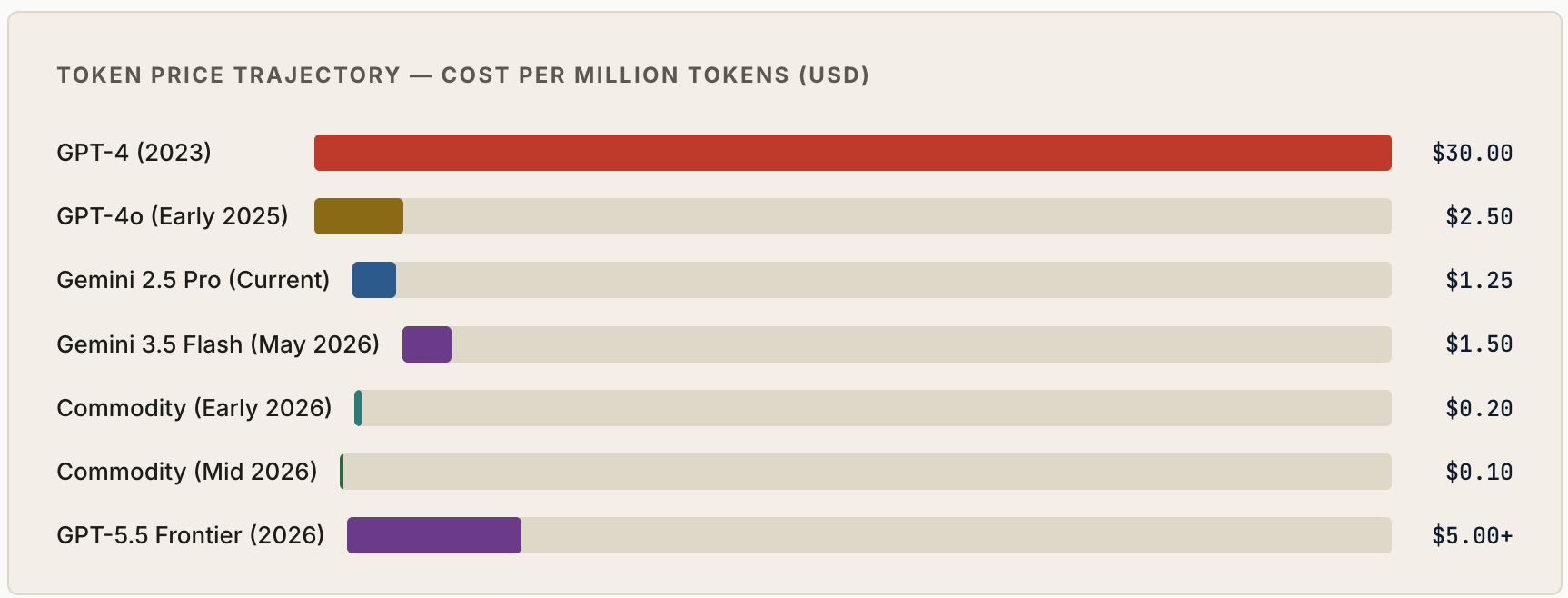
The drivers of this collapse are worth examining carefully because they are not uniform — different factors dominate at different points on the curve, and understanding the mechanism helps investors forecast where the curve goes from here. The initial decline from $30 to $2.50 was primarily driven by architectural improvements in the GPT-4 lineage and the introduction of distilled models that could approximate GPT-4 quality at a fraction of the compute cost. The subsequent decline from $2.50 to commodity levels below $0.10 has been driven by an entirely different set of forces.
Open-source model proliferation is the first and most disruptive factor. Meta’s decision to release Llama model weights publicly created a price floor that proprietary providers have been forced to match or exceed in value. When a sophisticated buyer can run a Llama 4-class model — Meta released Llama 4 Scout and Llama 4 Maverick in April 2025, natively multimodal MoE models — on their own infrastructure at near-zero marginal cost per token, the pricing power of closed API providers compresses dramatically. This dynamic is structural, not cyclical — Meta’s incentive to commoditize the model layer (where it has no direct revenue) to strengthen its position in advertising and social AI (where it does) is durable and unlikely to reverse.
Software optimization has been equally important. Techniques like speculative decoding — where a smaller “draft” model generates candidate tokens that the larger model then validates in parallel — reduce inference compute requirements by 2-3x without meaningful quality degradation. Mixture of Experts (MoE) architectures, deployed at scale in models like GPT-4o and Google’s Gemini, route each token through only a subset of the model’s parameters, achieving frontier-class quality while consuming substantially less compute per token than dense transformers of equivalent nominal size. Quantization — reducing the precision of model weights from 32-bit floats to 8-bit or even 4-bit representations — cuts memory bandwidth requirements dramatically, enabling faster and cheaper serving on the same hardware. Combined, these techniques represent a 2-5x reduction in inference compute requirements with essentially no externally visible quality impact.
The Counterforce: Reasoning Models
Just as base model inference costs were collapsing, OpenAI released the o-series reasoning models — o3 ($2.00/$8.00 per million input/output tokens) and o4-mini ($0.55/$2.20 per million tokens) — that deliberately use massively more compute at inference time via extended chain-of-thought generation. These models cost significantly more per query than standard models, with the premium frontier (GPT-5.5) priced at $5.00/$30.00 per million tokens. The token price curve is simultaneously deflating at the commodity end and inflating at the premium end, creating a barbell market structure that complicates any single-line narrative about inference economics.
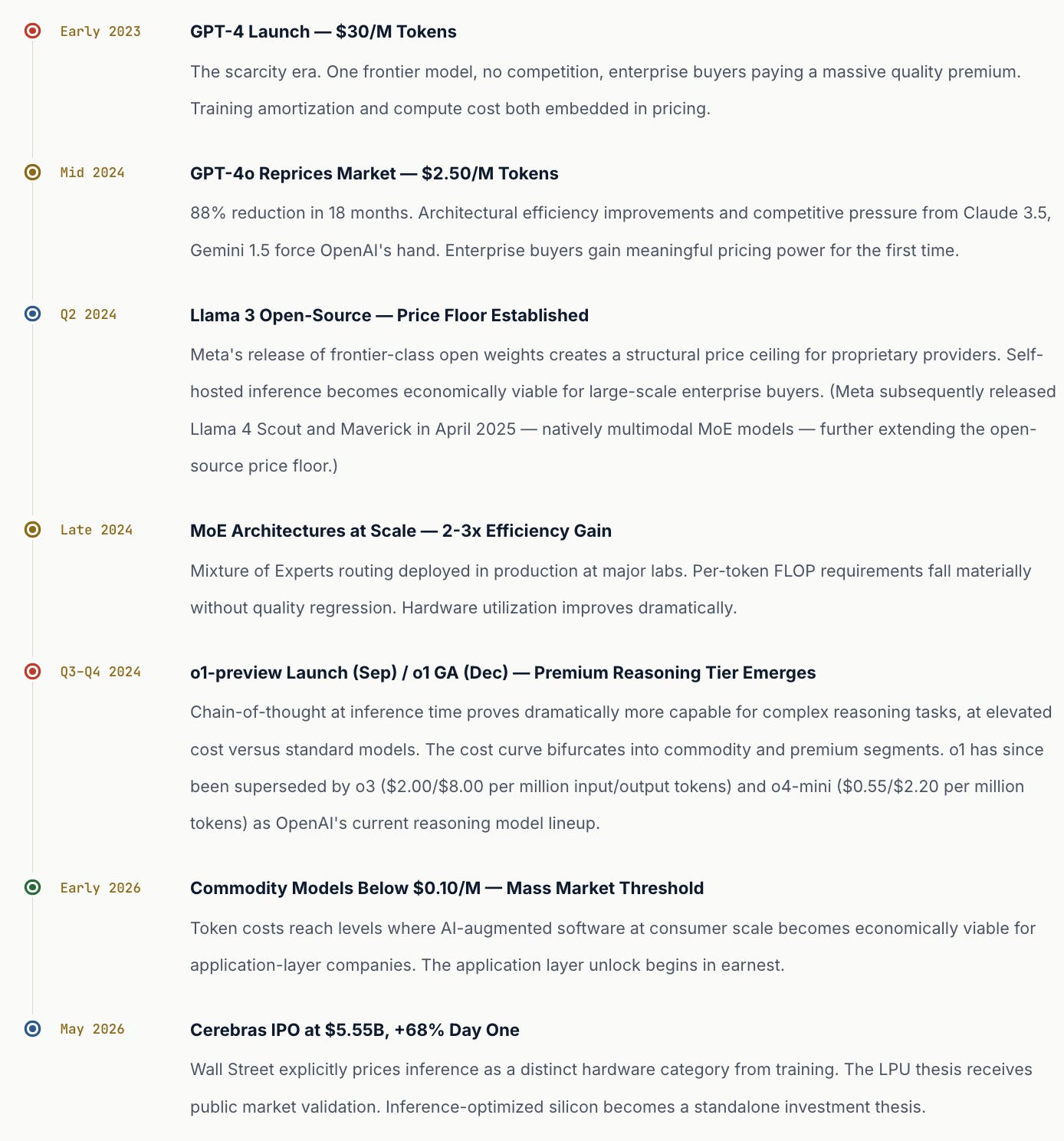
What is most striking about the token price timeline is not any single data point but the compounding of multiple independent efficiency vectors simultaneously. Hardware is improving. Software is improving. Architectures are becoming more efficient. Open-source competition is compressing margins. Any one of these forces would produce meaningful deflation; their combination is producing deflation at a pace that is genuinely historically unusual. The inference market of 2026 bears essentially no resemblance to the inference market of 2023, and the inference market of 2030 will bear equally little resemblance to today’s.
04
