
The AI Compute Backlog Is Deeper Than Anyone Will Tell You
Hyperscalers committed $630 billion to AI infrastructure in 2026 alone. Blackwell GPUs are sold out through at least mid-2026 with a 3.6 million-unit backlog and 36-to-52-week delivery lead times.


The AI compute shortage is not a temporary supply chain disruption. It is a structural mismatch between what the world’s largest technology companies have decided to spend — $630 billion in a single year — and the physical infrastructure required to deploy that capital. Nvidia’s Blackwell GPUs are sold out with a backlog of 3.6 million units. The advanced chip packaging process required to build them (TSMC’s CoWoS) is fully allocated through at least mid-2027. The HBM memory that makes these chips perform is booked 12–15 months out with three suppliers in the world. And the power grid — the actual electricity needed to run the chips once they arrive — is failing to keep pace, with 7 gigawatts of planned U.S. datacenter capacity stalled behind permitting delays and grid interconnection queues measured in years, not months.
The rest of the semiconductor industry is responding, and the response is real: AMD’s MI400 launches in 2026 with next-generation memory bandwidth. Google’s TPU controls 58% of the custom cloud AI accelerator market. Amazon’s Trainium2 delivers 30–40% better price-performance for inference workloads. Microsoft and Meta are building custom silicon to reduce their Nvidia dependence. But demand is not waiting for supply to catch up — it is accelerating. Reasoning AI models (o3, Gemini 2.0 Ultra, Claude 4 Opus) use 100 to 1,000 times more compute per query than the GPT-3.5-era models that triggered the original buildout. Agentic AI — software that runs autonomously, continuously, in the background — is adding a baseline compute load that has no off-switch. The question this report attempts to answer: how deep is the hole, who is helping fill it, and is a world where compute demand and compute supply are in balance even theoretically achievable?
01
The Shape of the Hole — Measuring the Gap Between Demand and Supply
The easiest way to understand the compute backlog is to follow the money. In 2022, the five largest hyperscalers — Amazon, Microsoft, Google, Meta, and Oracle — collectively spent approximately $120 billion in capital expenditure. In 2023, that number grew to roughly $170 billion. In 2024, it reached $220 billion. In 2025, it hit $400 billion. The guidance for 2026 is $600–630 billion combined — a fivefold increase in four years, with roughly 75 cents of every dollar targeting AI infrastructure: GPUs, datacenter construction, networking, and power. No industrial sector in history has scaled capital deployment at this pace for this duration.
What that capital is trying to buy is a finite resource. There are effectively three entities capable of manufacturing the advanced AI accelerators that hyperscalers need: Nvidia (which designs but does not fabricate), AMD (which also designs but does not fabricate), and the hyperscalers themselves through custom silicon programs. All three depend on a single manufacturer — TSMC — for the most advanced process nodes (N4 and N3). TSMC’s capacity is allocated years in advance across Nvidia, Apple, AMD, Qualcomm, and dozens of others. When demand from AI accelerators spikes, it does not displace Apple’s iPhone chip production — Apple has contractual priority and pays in advance. Instead, AI accelerators compete for incremental wafer capacity that TSMC has been building out over a multi-year expansion that cannot be accelerated past a certain rate of construction, tooling, and talent development.
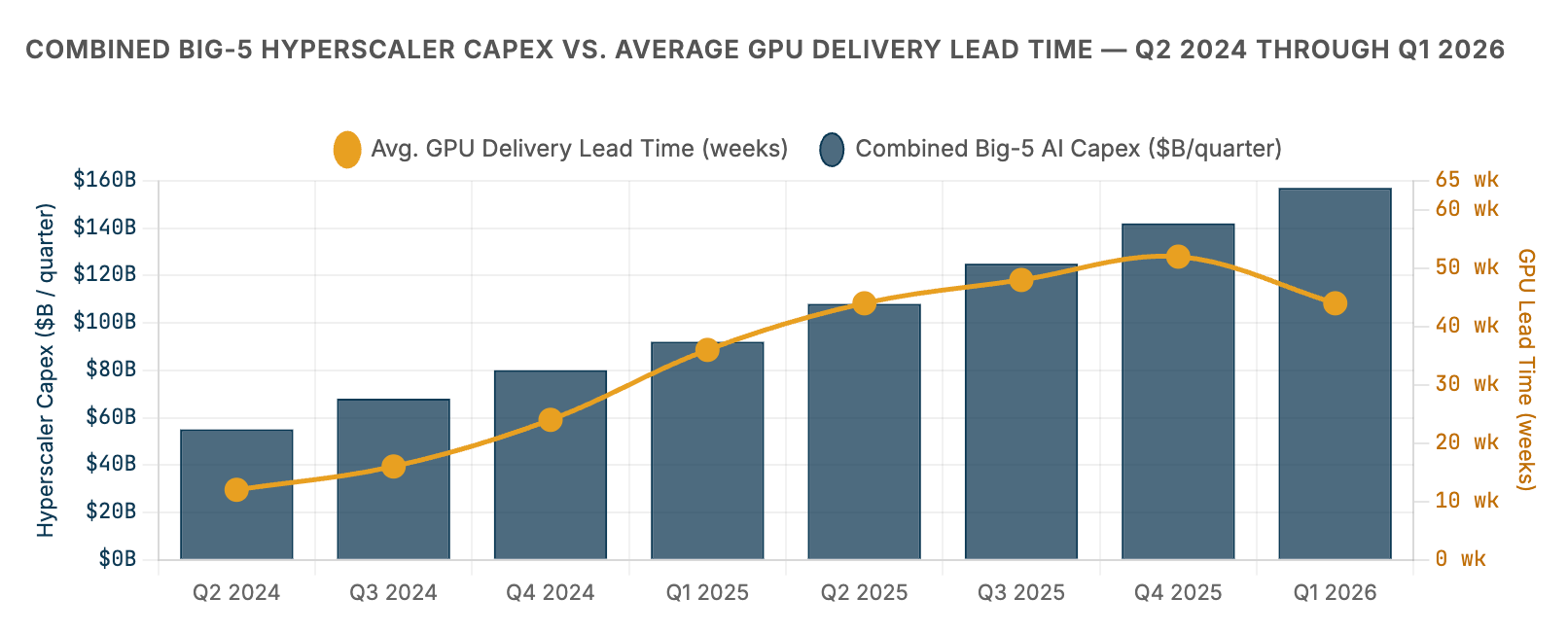
The chart above captures the fundamental asymmetry of the compute supercycle: capital spending has increased roughly threefold in six quarters while GPU delivery lead times have expanded from 12 weeks to 36–52 weeks — and the two lines are not converging. The hyperscalers are spending faster than the supply chain can respond. This would be a temporary dislocation if demand were static — more spending eventually means more supply, and prices normalize. What makes the AI compute backlog structurally different is that demand is not static. Every quarter, the software being trained and deployed grows more compute-intensive. Every advance in model capability creates a new class of applications that requires more infrastructure to run. Supply is chasing a target that keeps moving.
02
The Four Bottlenecks — Why Supply Cannot Simply Scale to Meet Demand
The compute shortage is not one problem. It is four interlocking problems, each of which would be constraining on its own, and which together create a situation where solving any single bottleneck does not resolve the overall supply shortage. Understanding each separately is essential to judging when — or whether — relief is coming.
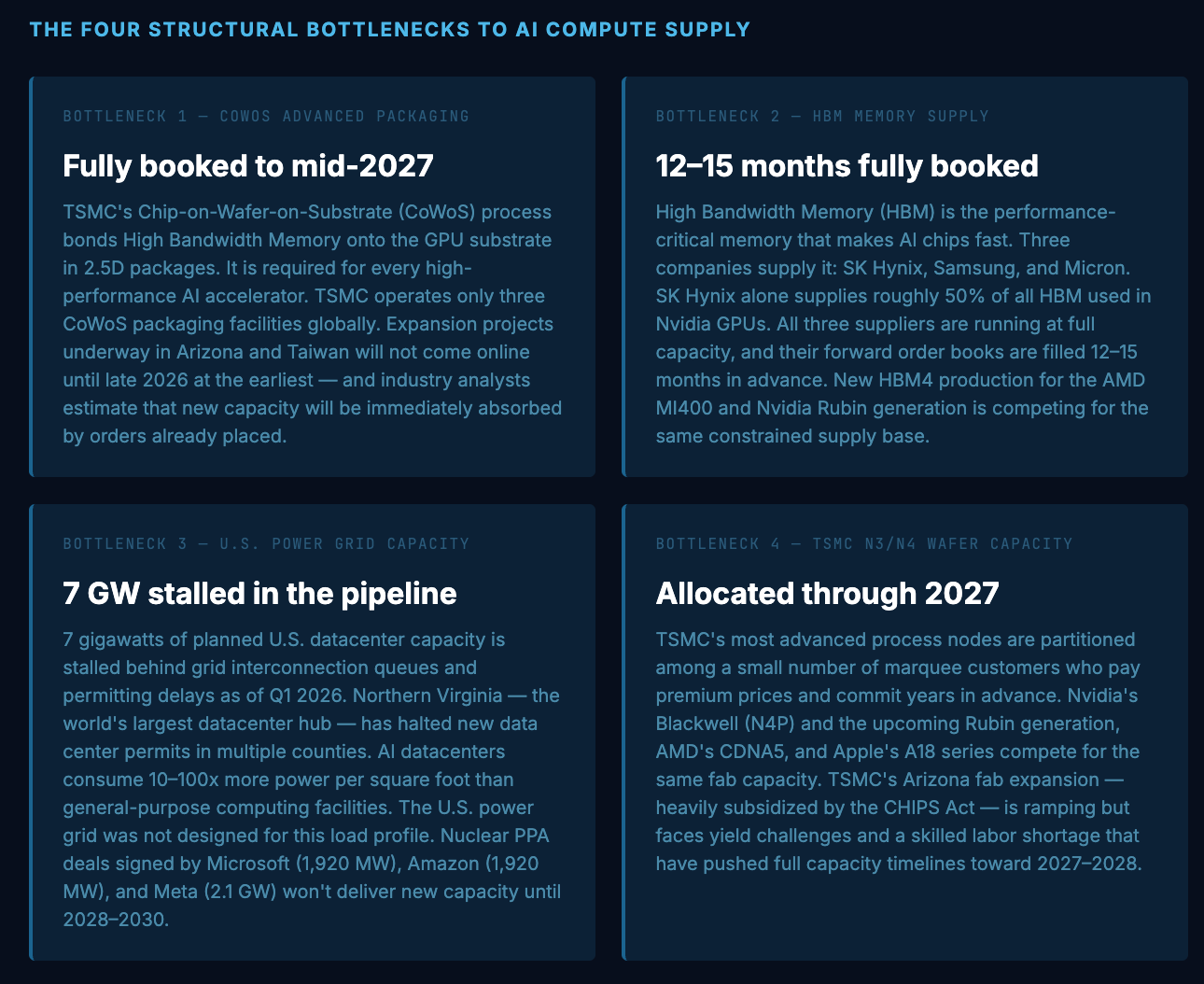
The most important thing to understand about these four bottlenecks is their interdependence. Solving the CoWoS packaging shortage alone does not help if HBM is still constrained. Solving both does not help if the power grid cannot support the additional datacenters needed to house the chips. And solving all three still leaves the question of whether TSMC can produce enough leading-edge wafers to satisfy demand from Nvidia, AMD, Apple, and the hyperscalers’ custom silicon programs simultaneously. Each bottleneck is necessary to solve but none is sufficient — and they are operating on different timescales, with power grid expansion measured in years longer than semiconductor capacity expansion.
03
Beyond Nvidia — Who Else Is Helping Close the Gap?
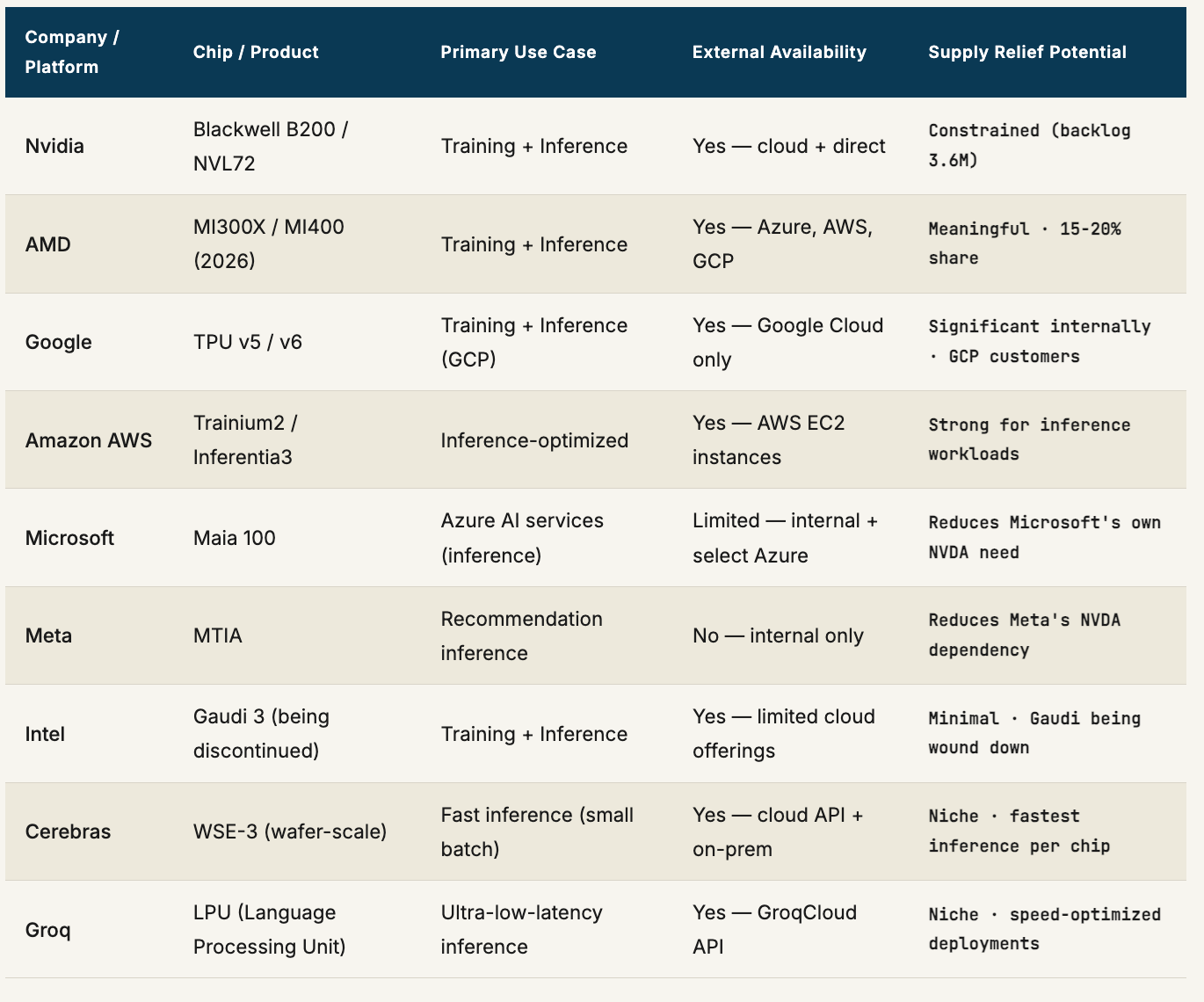
Nvidia’s market share in data center AI accelerators was approximately 86% in 2024 and is projected to compress to around 75% by the end of 2026 — not because Nvidia is losing, but because the overall market is growing faster than Nvidia can supply, and alternative platforms are capturing incremental demand. Here is where the real supply relief is coming from, company by company.


The combined effect of AMD’s MI400 ramp, Google’s TPU deployment, and AWS Trainium2 availability is meaningful but not sufficient to close the gap in 2026. Industry analysts estimate that alternative silicon will capture approximately 25% of AI compute demand by year-end 2026 — up from roughly 14% in 2024. That is real market share movement. It is not enough to bring lead times back to pre-supercycle norms.
04
The Supply Pipeline — What’s Coming and When

05
The Competitor Landscape — A Scorecard
06
